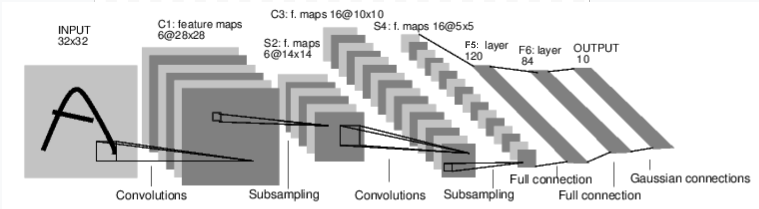
Simple ConvNet
Train a simple Convnet
Neural networks can be constructed using the torch.nn package
An nn.Module contains layers, and a method forward(input)that returns the output.
A typical training procedure for a neural network is as follows:
Define the neural network that has some learnable parameters (or weights)
Iterate over a dataset of inputs
Process input through the network
Compute the loss (how far is the output from being correct)
Propagate gradients back into the network’s parameters
Update the weights of the network, typically using a simple update rule:
weight = weight - learning_rate * gradient
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d -> view -> linear -> relu -> linear -> relu -> linear -> MSELoss -> loss
Define the network
Let’s define this network:
tensor.view(-1,n), Returns a new tensor with the same data as the self tensor but of a different shape. the size -1 is inferred from other dimensions
Inputs
torch.nn only supports mini-batches. The entire torch.nn package only supports inputs that are a mini-batch of samples, and not a single sample. For example, nn.Conv2d will take in a 4D Tensor of nSamples x nChannels x Height x Width.
If you have a single sample, just use input.unsqueeze(0) to add a fake batch dimension.
Datasets (MNIST)
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
root (string) – Root directory of dataset where
MNIST/processed/training.ptandMNIST/processed/test.ptexist.
Loss Function
A loss function takes the (output, target) pair of inputs. There are several different loss functions https://pytorch.org/docs/nn.html#loss-functions``
Update the weights(Optimization)
various different update rules such as SGD, Nesterov-SGD, Adam, RMSProp, etc.
Last updated